
How to Build a RAG Pipeline for AI: Improve LLMs with Retrieval-Augmented Generation
LLM Limitations and How RAG Solves Them

Large Language Models (LLMs) like GPT-4, Claude, and Gemini are incredibly powerful, but they have some major limitations:
Limited Context Window – LLMs can only process a fixed number of tokens per prompt.
Static Knowledge – Once trained, they cannot update their knowledge unless retrained on new data.
Hallucinations – LLMs sometimes generate false or misleading information because they try to predict plausible answers rather than retrieving factual data.
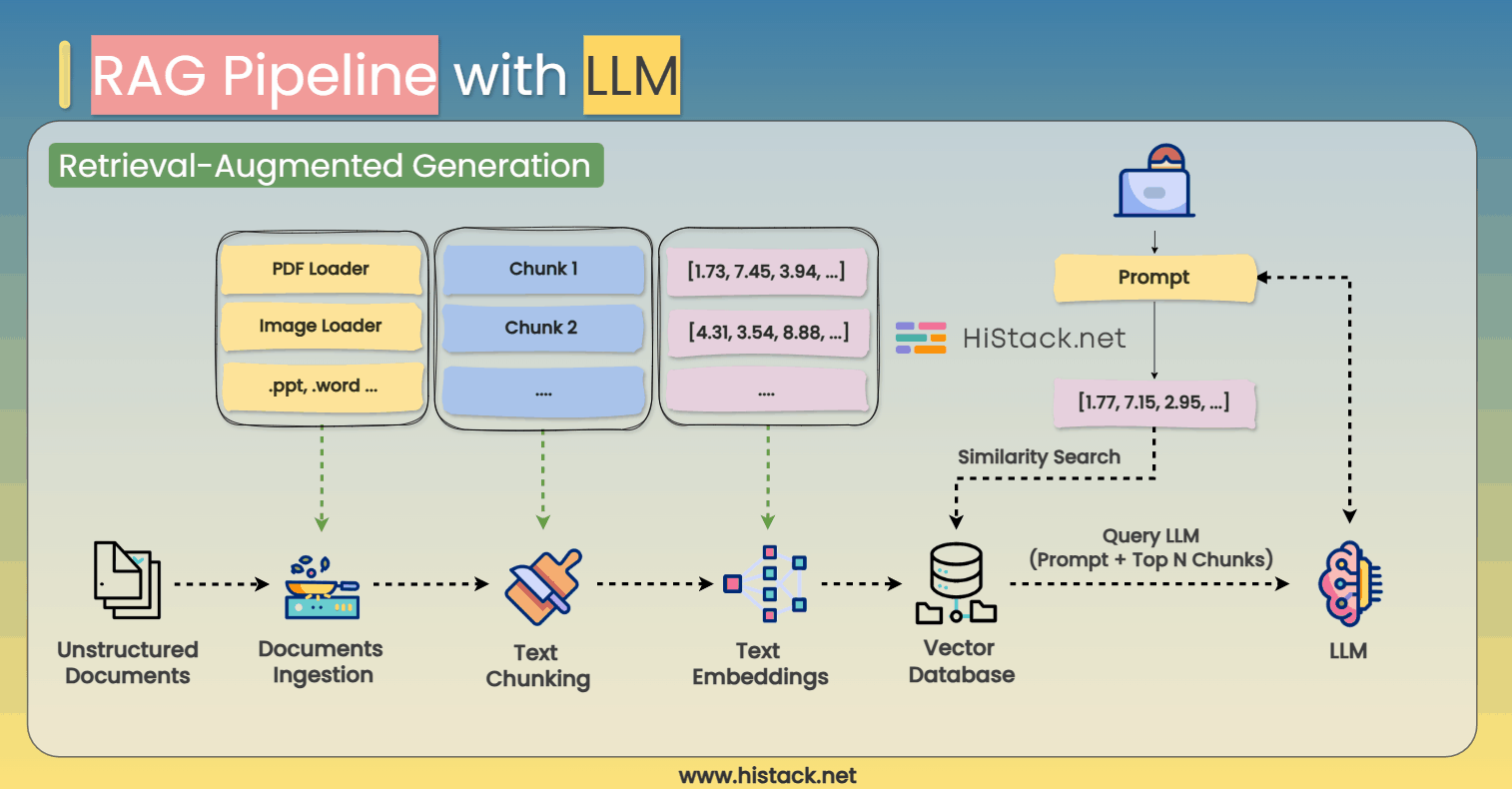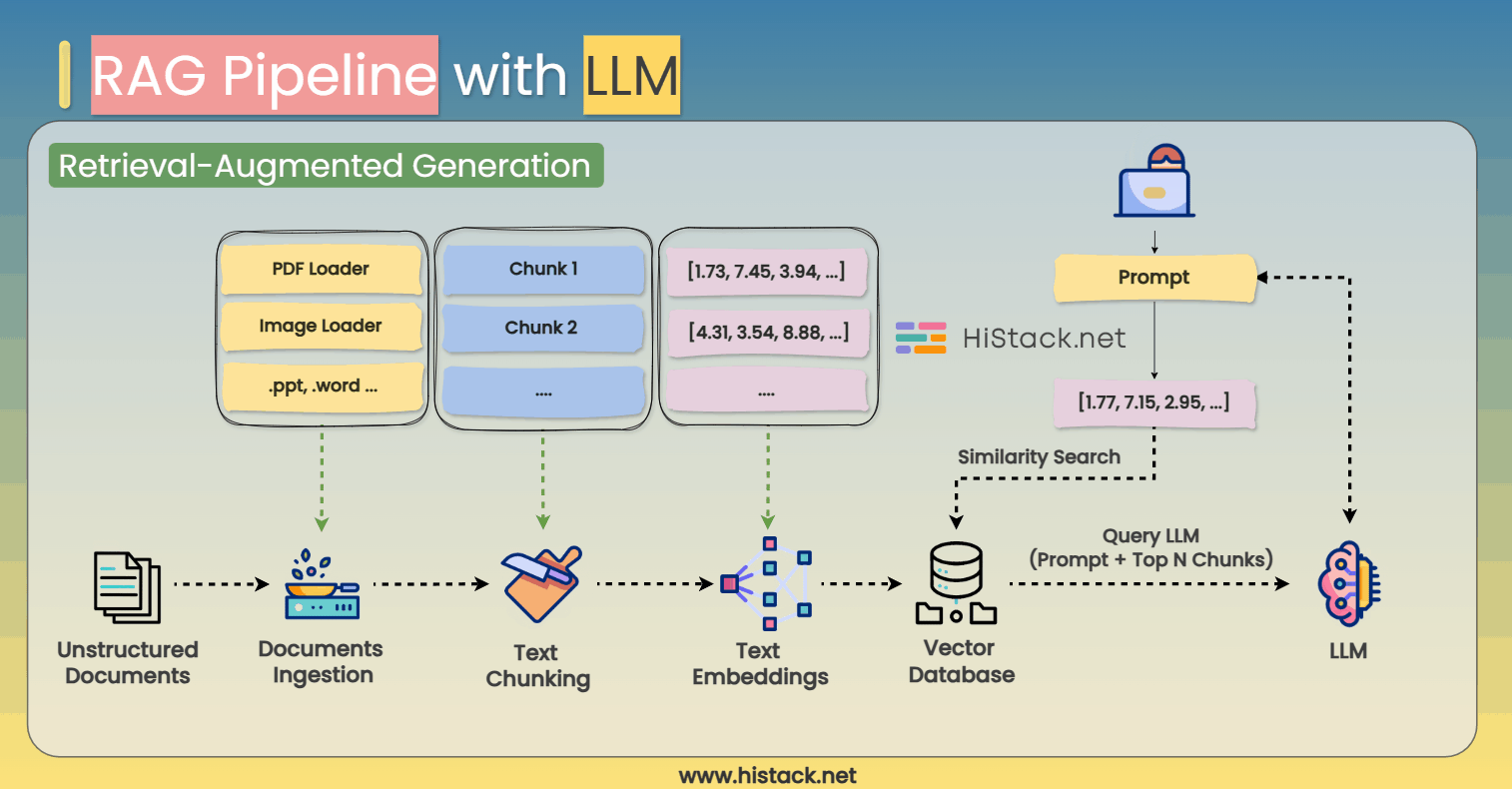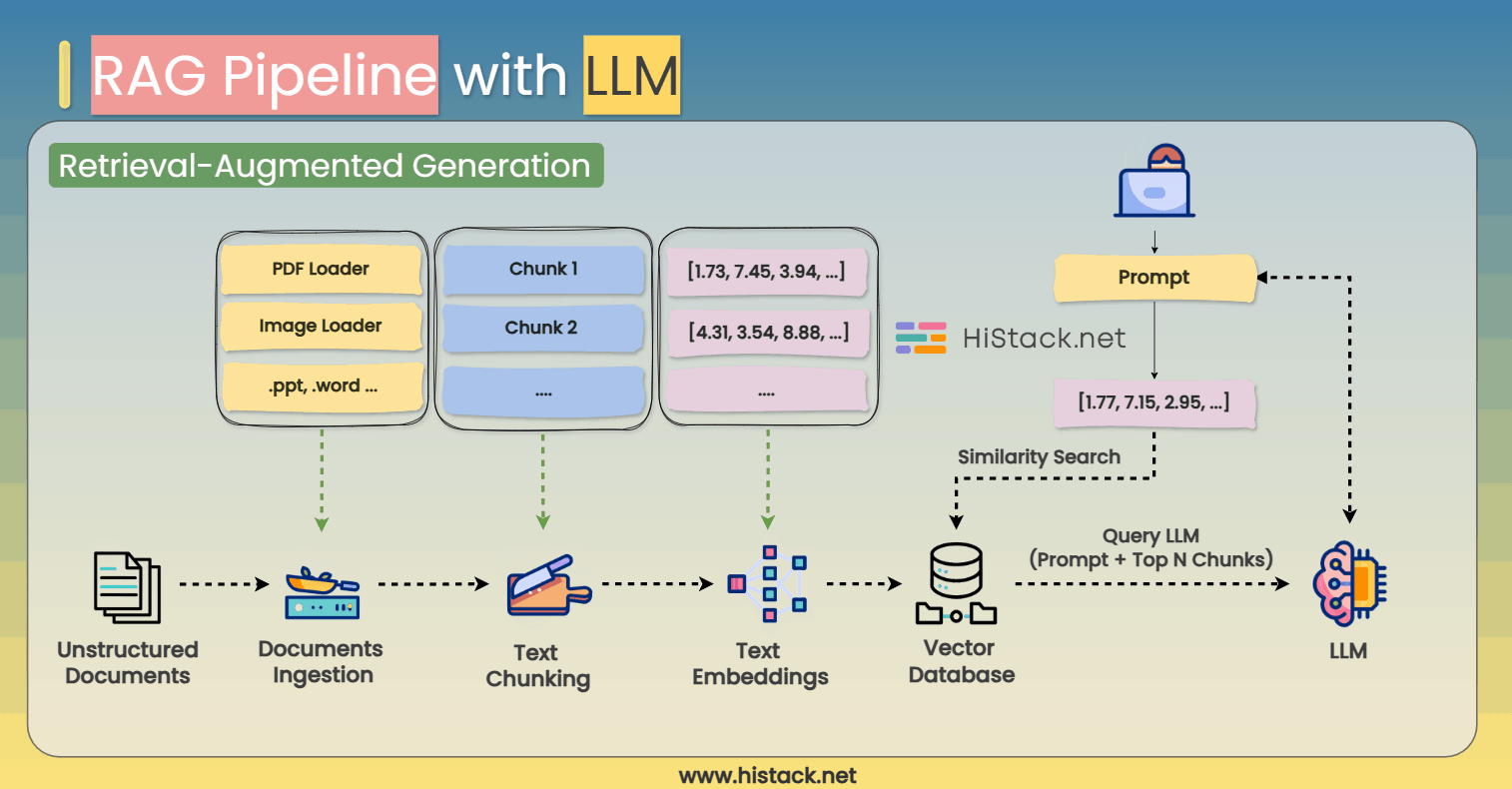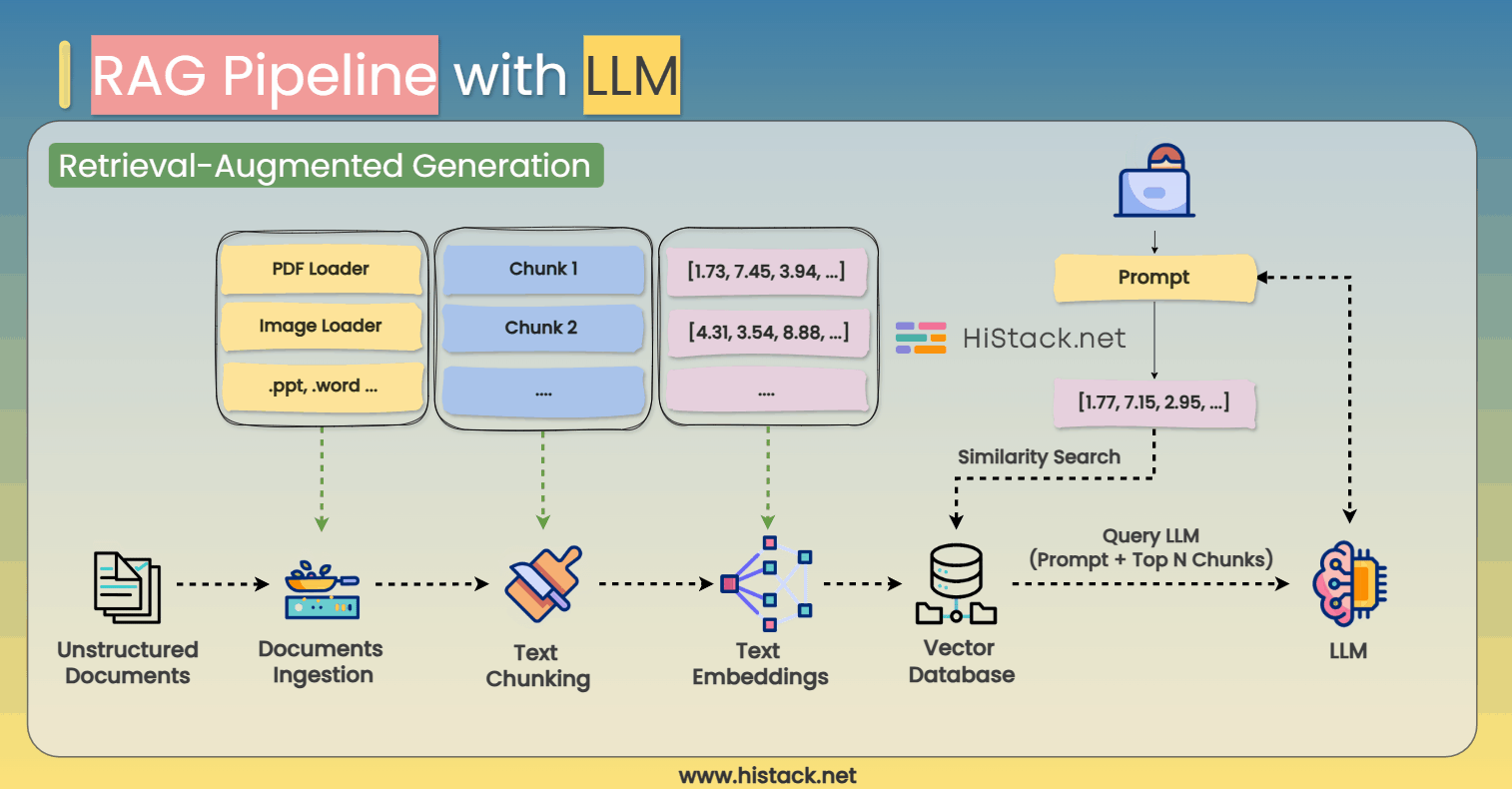
RAG (Retrieval-Augmented Generation) enhances LLMs by allowing them to retrieve relevant external information in real time, rather than relying solely on their pre-trained knowledge. This significantly improves accuracy, making AI models more useful for real-world applications like chatbots, customer support, and research assistants.
How Does a RAG Pipeline Work?
Step 1: Ingesting and Processing Documents
Before an LLM can retrieve external knowledge, it needs a source of information. The first step is document ingestion, where raw data is extracted and processed from different formats, including:
Text files (PDFs, Word documents, PowerPoint slides)
Images & Scanned Documents (processed via Optical Character Recognition - OCR)
Web Pages & Databases
Why is document ingestion necessary?
LLMs can’t read raw files directly.
Extracting and formatting text ensures structured data processing for later retrieval.
💡 Tools for document ingestion:
LangChain – Handles multiple file formats efficiently.
PyMuPDF – Extracts text from PDFs.
Tesseract OCR – Converts images and scanned documents into text.
Step 2: Splitting Text into Chunks
Once the documents are ingested, they are broken down into smaller chunks for efficient retrieval.
Why do we split text into chunks?
LLMs work best with small, manageable pieces of text rather than large documents.
Smaller text chunks allow for faster and more relevant search results.
Best practices for text chunking:
Use overlapping chunks to preserve context.
Adjust chunk sizes based on document type (e.g., longer chunks for structured text like legal documents).
Note: If you have a 1,000-word article, chunking might create 10 sections of 100 words each, making retrieval faster and more precise.
Step 3: Converting Text to Embeddings
Each text chunk is then converted into a numerical representation known as an embedding.
What are embeddings?
Embeddings are vector representations of text that help the system find semantically similar content instead of relying on exact word matches.
Example: The phrase "AI in healthcare" will have an embedding close to "Machine learning in medicine" because of their conceptual similarity.
💡 Popular embedding models:
OpenAI’s text-embedding-ada-002
Google’s BERT
Hugging Face’s Sentence Transformers
Step 4: Storing Data in a Vector Database
Once the text embeddings are generated, they are stored in a vector database for fast retrieval.
Why use a vector database?
It allows quick similarity searches to find the most relevant information.
It supports real-time updates, so new data can be added without retraining the LLM.
💡 Popular vector databases for RAG:
FAISS (Facebook AI Similarity Search)
Pinecone (Optimized for production environments)
Azure AI Search DB
Step 5: Querying the RAG Pipeline
When a user submits a question or search query, the system follows these steps:
Convert the query into an embedding (same way document chunks were converted).
Search the vector database for the most relevant chunks.
Retrieve the top N chunks (e.g., the most similar 3-5 pieces of text).
Combine the query and retrieved text to generate a complete response.
Why is this better than traditional LLMs?
Instead of relying only on its pre-trained knowledge, the LLM gets real-time information from retrieved documents.
This makes the generated response more accurate and contextually relevant.
Step 6: Generating the Final Response
Finally, the retrieved text is fed into the LLM alongside the user query. The model processes the expanded context and generates a response that is:
More accurate
Less prone to hallucinations
Based on real-time information
This step completes the loop, allowing AI models to provide data-driven, up-to-date answers.